好幾個月沒寫 用這篇把 Veeam 最後一段補起來
這篇主要描述當初在Datacenter導入 Veeam B & R 設計, 踢到鐵板, 以及改善過程
主要分三個階段吧
一開始:槍在手 跟我走
最早Veeam 也只是在Lab做完POC.也沒想過(機會)要跟遠在半個地球外的原廠 Consultant 討論架構
就直接腦子一熱 架構圖畫了 自認為可以衝了 就實裝在手上最大的 Datacenter了

- Veeam Proxy 直接去抓 VM Storage 的 VMDK. 完全不用透過 ESXi, 減少 ESXi 負擔
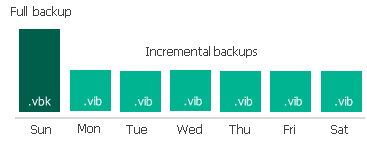
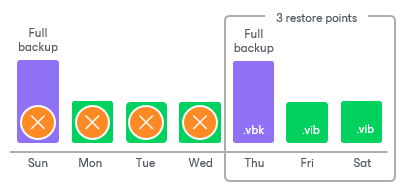
- Veeam backup incremental policy, 只有第一次 VM backup 需要 Full backup, 之後永遠都是 incremental backup. 由 Veeam 在後端合成 full backup set. 可以減少 VM storage 負擔
- 後端 Backup Repository 使用實體機 Windows Server + Storage (4T 7.2K x 84顆).
- 利用 Windows File System level de-dupl + compress, 期望減少後端實際空間消耗
想當然爾 踩到超級大地雷 Lab 環境終究是 Lab.
在幾千個 VM 運作環境下 任何小問題都會被放大
- 第一個踩到的地雷, 實體 Windows File Server 聯外 backup network 1G x 4 (LACP)
要伺候十個 Veeam Proxy (1G x 1) 同時丟東西進來 炸了 - 第二個爆炸的地雷 Windows de-duple 需要花兩到三天才會完成一輪 de-dupl/compress 程序, 結果配上 Veeam incremental backup policy. De-dupl/compress 還沒跑完 就被 Veeam 清掉, 又產生一份新的 full backup set. 永遠沒有拿到 de-dupl/compress的好處, 反而 de-dupl 產生的 library 越長越大
最後Daily VM backup 吃不下一百個...超過的話 Daily backup 就變成bi-day backup.
可是我有上千個 VM 耶
被地雷炸過之後:想辦法找到原廠聊聊天
一頭熱之後 被炸得七暈八素 當然是跟原本說明的人抱怨(幹礁)
還好老闆跟廠商關係好 想辦法找到原廠來幫忙看架構是否有得調整
結果就變成下面了

改變的地方
- 放棄 Windows File System De-dupl/Compress, 列為拒絕往來戶
- 改在 Veeam Proxy 讀取 Data, 送到 storage 之前
靠 Veeam 自己的 in-line de-dupl/compress 把 data 縮小一圈才送出去
免得 File server 變成 Fire server. - 消耗 Veeam Proxy (ESXi) 上面的 CPU, 不過相對於其他 resource, VM farm CPU 平均使用率算低的
修成這架構之後 總算可以吃下數百個 VM 的 daily backup
微調 微調 再微調:Password改改改, Patch上上上
後來因為策略需求 每隔一段時間都要上 Windows Patch
每隔一段時間也要改 service account password
就又改了一些地方

- Veeam Proxy 不再直接進VM storage mount disk. 改成透過 ESXi 去讀取 VMDK
因為之前設計 Veeam Proxy 一旦 mount VMDK, 若此時 Proxy 因為上Patch重開機, Backup job會掛掉就算了, VMDK 就會一直掛在這 Veeam Proxy上不會自己解除
別的Proxy也不能繼續把 Backup 完成. 需要人為去把 mount 清掉
要嘛, 要上Patch之前把所有Backup都停掉. 要嘛 每次手動清 mount disk
個人雖然沒有一分鐘幾十萬上下, 我也是會發懶的.
想來想去就犧牲掉一部分的 ESXi resource. 讓 Veeam Proxy去 ESXi抓資料囉
其中要是 Proxy 重開機, Job retry 會有另一個 Proxy 去接手完成 - Service account 整併
因為初期每次改Password都要去各地方改, 後來就盡量整併 可以少打Password的地方就少打 最後就是用 script + schedule job
結論:最後剩下的
- Veeam forever incremental policy
- File server 就單純作 File server
- Proxy 消耗 ESXi CPU resource 作 data de-dupl/compress
- 考慮減少避免Patch負擔 Veeam 直接讀 VM Storage 的方式捨棄, 確認隨時都可以上Patch, 隨時任何一個 Veeam component/server 都可以重開機
疑? 我好像是因為太愛玩才會在一開始被炸翻的吼